Self-Evolving Agent: Architecture Design for AI That Grows Its Own "Limbs"
Core Concept: From Fixed Foundation to Dynamic Evolution
Traditional AI Agent systems typically require pre-defining all tools and capabilities, but this approach hits bottlenecks when facing complex and varied tasks. Self-Evolving Agents take a different approach:
- LLM + Fixed Foundation (executor / storage) Never Changes: The core brain and execution environment remain stable
- Through Continuous Task Loops → Automatically Grow New "Limbs" (tools / mini agents): Automatically generate new capabilities when encountering new requirements
- These Limbs Are Stored for Reuse: Accumulate a knowledge base that gets stronger with use
- "Training Data" Is: Task Description + 100% Confirmed Correct Results (Starting with ~20 Sets): No need for massive datasets, just high-quality standard answers
This concept essentially does:
Program search using "task failure → analyze failure reason → generate new capability → retry" instead of modifying LLM weights.
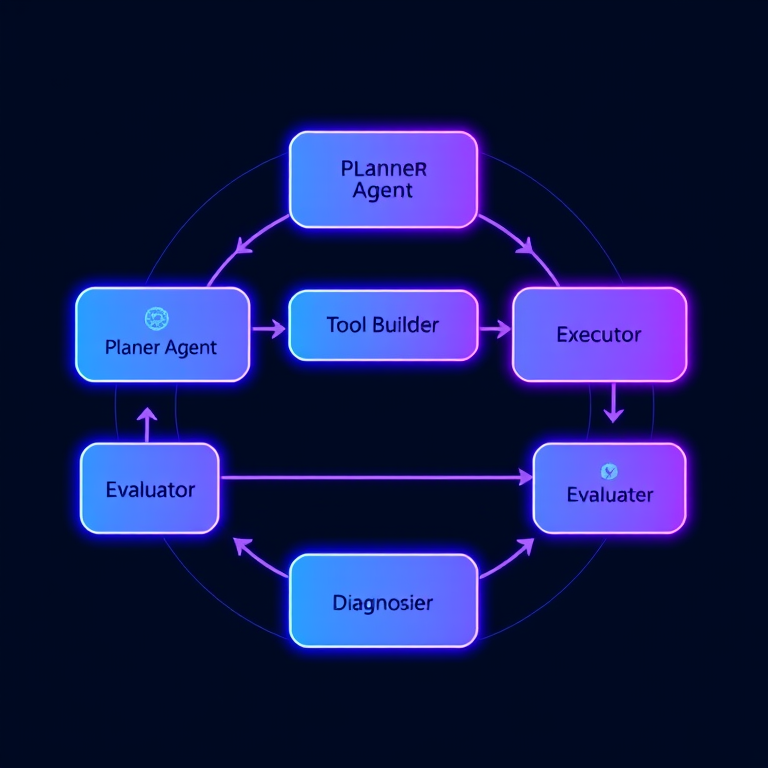
Architecture Design: Six Core Components
The entire system consists of six core components, forming a complete self-evolution loop:
1. Planner Agent (Planner)
Responsibility: Analyze tasks and produce solution plans
- Input: Task description + Currently registered tool list
- Output:
- A "solution plan": What steps are needed
- Which existing tools to use
- Which capabilities appear to be "missing"
For example, for the task "Find all Adobe products", it might produce:
Plan:
1. I need "web search" capability → Check if tool library has it
2. If search_web doesn't exist, create one first
3. Then use search_web('Adobe all products') to find official product page
4. After downloading page content, parse product list
2. Capability Checker
Responsibility: Check if required capabilities exist based on Planner's plan
- Check if needed tools already exist (Tool Registry)
- If a capability doesn't exist (e.g.,
search_web), mark it as needing to be built
3. Tool Builder Agent (Tool Builder)
Responsibility: Generate Python tool files based on "requirement description" + allowed dependencies
For example, requirement:
Requirement: Create a search_web(query: str) -> str function,
using requests + BeautifulSoup to fetch HTML from the first few links of Google search results.
Start with MVP, can fix later if wrong.
It outputs Python source code:
# tools/search_web.py
import requests
from bs4 import BeautifulSoup
def search_web(query: str) -> str:
# Simple implementation using search API or directly hitting specific sites...
...
Then Executor runs simple tests in sandbox (e.g., basic import, simple call test).
4. Executor
Responsibility: Execute the entire pipeline following Planner's listed steps after tools are available
- Use
search_webto find Adobe product page URL - Fetch webpage HTML
- Use built-in/existing parser to extract product list
Produces final output result.
5. Evaluator
Responsibility: Compare result with provided gold_output
- Complete match → Task successful, record "this tool combination works"
- No match → Task failed → Send to Diagnoser for problem analysis
Supports multiple evaluation methods:
exact_match: Exact matchpartial_match: Partial match (calculate keyword match rate)semantic_similarity: Use LLM to evaluate semantic similarity
6. Diagnoser (Diagnostic Agent)
Responsibility: Review logs, error messages, differences, summarize failure reasons and recommend next steps
For example:
- "search_web can only fetch static pages, but this page is a dynamic site → need render_dynamic_page capability"
- "HTML is messy with lots of irrelevant information → need a stronger clean_html / extract_products tool"
Then return to Tool Builder → generate new tool → run task again.
This is the evolution cycle in the concept:
- STEP1: Missing search → Generate
search_web - STEP2: Missing dynamic rendering → Generate
render_dynamic_page - STEP3: Missing cleaning → Generate
clean_product_list
Fixed Foundation
These are the "foundation", built first and never changed:
1. LLM API Itself
The GPT-class models currently in use, serving as the "brain".
2. Python Execution Environment (Sandbox)
- Can dynamically create files, import new tools
- Can restrict permissions (prevent random file deletion, random API calls)
3. Tool Registry
A simple structure, for example:
{
"search_web": {
"type": "python_function",
"path": "tools/search_web.py",
"signature": "search_web(query: str) -> str",
"description": "Fetch static web pages using HTTP"
},
"render_dynamic_page": {
"type": "python_function",
"path": "tools/render_dynamic_page.py",
"signature": "render_dynamic_page(url: str) -> str",
"description": "Render dynamic websites to HTML using Playwright/Selenium"
}
}
Agents can "add" and "modify" tools in this list.
4. Task and Standard Answer Dataset
Your prepared 20 sets (or more):
{
"task_id": "adobe_products",
"instruction": "Find all Adobe products, output as list",
"gold_output": "...your confirmed correct result...",
"eval_method": "exact_match / partial match strategy"
}
Training Method: From 20 Task Sets to Stable System
"Training" here can be divided into two layers:
Layer One: Actual Tool / Agent Process "Search + Filter"
This is definitely achievable:
For each task:
- Continuously run "try → fail → generate new tool → retry → evaluate" loop
- Only keep versions that pass evaluation (tool code + usage flow)
Over time, you'll get:
- A GPT prompt set + tool library + invocation strategy that can stably solve these 20 task sets
This is somewhat like:
Searching for "program + tool combinations", with your Dataset as the 20 test questions.
Layer Two: Meta-Learning (Optional)
If you have permission to do "fine-tuning" or "prompt engineering", you can further:
Store successful logs as "demonstration data"
- Prompt: Task description + tool list + log
- Output: Final successful tool invocation plan / chain-of-thought
Use these demonstrations:
- As "few-shot examples in system prompt"
- Or send for fine-tuning (if you can train your own model)
This way, when encountering "similar tasks" next time, Planner will have better sense from the start, without needing to guess through many rounds.
Making the Loop Actually "Grow Mini Agents"
What you want: Newly generated items aren't just functions, but "mini agents". Implementation can:
Abstract "Capabilities" as Agents, Not Just Functions
For example:
SearchAgent- Internally calls
search_web,render_dynamic_pageand other tools - External interface only:
search_and_extract(query) -> structured_data
- Internally calls
ProductExtractorAgent- Specialized in extracting product names, categories, etc. from HTML.
Evolution Direction of Loop:
Initially just "functions":
search_webrender_dynamic_pageparse_products
When these functions stabilize, Planner can discover:
- "Every time doing 'find products' task, need to call these three tools in similar order"
- Then LLM proposes:
- "Let's encapsulate it as a
ProductSearchAgent"
- "Let's encapsulate it as a
Tool Builder produces a class / module:
# agents/product_search_agent.py
from tools.search_web import search_web
from tools.render_dynamic_page import render_dynamic_page
from tools.parse_products import parse_products
class ProductSearchAgent:
def run(self, brand: str) -> list[str]:
# 1. search_web finds brand product page
# 2. render_dynamic_page renders
# 3. parse_products extracts
...
- Tool Registry now also treats
ProductSearchAgentas a "capability", Planner can directly call it next time without redesigning pipeline.
This matches what you said:
Limbs can even include other mini agents.
Essentially:
From "common tool combinations" → Automatically encapsulate into a new agent, and register into capability graph.
Three Real-World Pitfalls to Watch
1. False Confidence / Hallucination
LLMs easily "think they're right" but actual results are wrong.
So must rely on "computable evaluation" (your provided gold output), don't trust LLM saying "I think this result is OK".
2. Poor Tool Quality Leading Astray
Without testing, it will write code that runs but has twisted logic.
At minimum need:
- Basic unit tests (types, simple cases)
- Effectiveness tests (try running 2-3 sample tasks)
3. Tool Explosion / Capability Duplication
Over time will grow many tools with similar functions.
You can periodically run a "Refactor Agent":
- See which tools have overlapping functions
- Propose merge / cleanup
- Similar to code refactoring.
Implementation Suggestions: Start with Minimal Version
If you want to start implementing this loop, I'd suggest first step:
Prepare those 20 "task + standard answer" sets (JSON)
Build a minimal version:
- Tool Registry (can manually write a few tools first)
- Executor
- Evaluator (compare result vs gold)
Let LLM handle:
- Planner + Diagnoser, but don't let it modify code automatically yet
- First observe how it proposes "what capabilities I'm missing", you manually write tools
After this flow stabilizes, replace "manual tool writing" step with Tool Builder + Python file writing.
Practical Application Scenarios
This architecture is particularly suitable for:
- Tasks requiring constant adaptation to new data sources: e.g., scraping product information from different websites
- Scenarios with similar task types but different details: e.g., "Find all products of company X"
- Complex tasks requiring combination of multiple capabilities: e.g., "search → parse → clean → format"
Conclusion
The Self-Evolving Agent architecture provides a new approach: Instead of pre-defining all capabilities, let the system automatically grow needed capabilities during task execution.
Advantages of this method:
- Strong adaptability: Automatically evolves when encountering new requirements
- Accumulative: Each solved task leaves reusable tools
- Controllable cost: Only need 20 sets of high-quality training data, no need for massive annotation
Of course, this also brings new challenges:
- Need stricter evaluation mechanisms
- Need to prevent tool quality issues
- Need to manage tool library complexity
But overall, this is a direction worth exploring, especially in scenarios requiring handling diverse tasks.