自我演化的 Agent:讓 AI 自動長出「手腳」的架構設計
核心概念:從固定基底到動態演化
傳統的 AI Agent 系統通常需要預先定義好所有工具和能力,但這在面對複雜多變的任務時會遇到瓶頸。自我演化的 Agent 採用不同的思路:
- LLM + 固定基底(executor / storage)永遠不變:核心大腦和執行環境保持穩定
- 透過不斷 loop 任務 → 自動長出新的「手腳」(tools / 小 agent):遇到新需求時自動產生新能力
- 這些手腳會被存起來,下次遇到類似任務就直接拿來用:累積知識庫,越用越強
- 「訓練資料」是:任務描述 + 你 100% 確定的正確結果(大概 20 組起跳):不需要大量資料,只需要高品質的標準答案
這個構想本質上是在做:
用「任務失敗 → 分析失敗原因 → 產生新能力 → 再嘗試」的程序搜尋(program search),而不是改 LLM 權重。
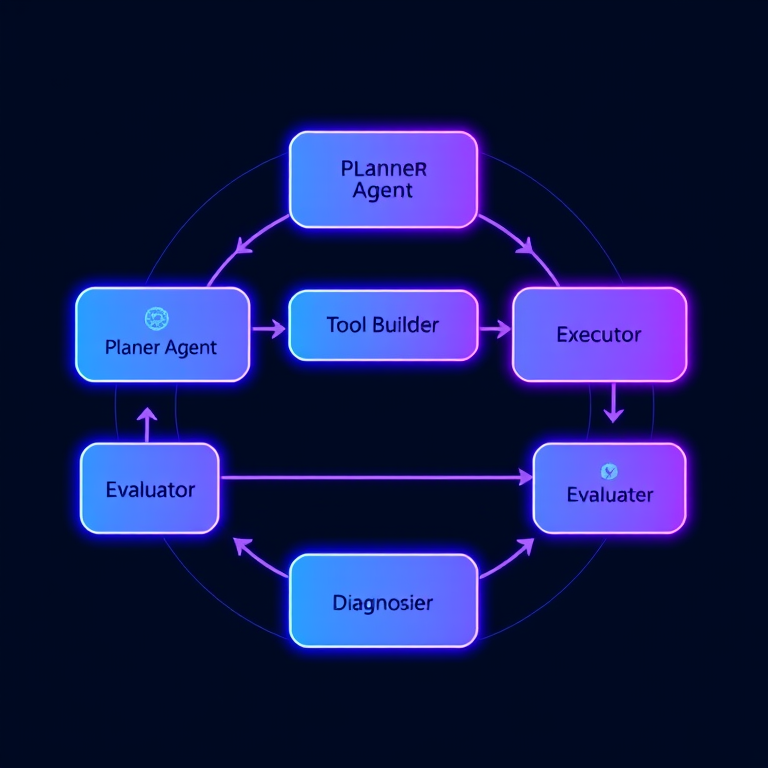
架構設計:六個核心組件
整個系統由六個核心組件組成,形成一個完整的自我演化循環:
1. Planner Agent(規劃者)
職責:分析任務,產出解題計畫
- 輸入:任務描述 + 目前已註冊的工具列表
- 輸出:
- 一個「解題計畫」:需要哪些步驟
- 用到哪些現有工具
- 哪些能力看起來「缺失」
例如對「找出 Adobe 所有產品」的任務,它可能產出:
計畫:
1. 我需要「搜尋網路」的能力 → 看工具庫有沒有
2. 如果沒有 search_web,就先建立一個
3. 然後用 search_web('Adobe all products') 找到官方產品頁
4. 下載該頁內容後,解析產品清單
2. Capability Checker(能力檢查器)
職責:根據 Planner 的計畫,檢查所需能力是否存在
- 檢查需要的工具是否已存在(Tool Registry)
- 如果某個能力不存在(例如
search_web),就標記為需要建造
3. Tool Builder Agent(造工具的小工)
職責:根據「需求描述」+ 你允許的依賴,產生 Python 工具檔
例如需求:
需求:建立一個 search_web(query: str) -> str 的函數,
用 requests + BeautifulSoup 把 Google 搜尋結果前幾個連結的 HTML 抓回來。
先做 MVP 就好,錯了再改。
它輸出的是 Python 原始碼:
# tools/search_web.py
import requests
from bs4 import BeautifulSoup
def search_web(query: str) -> str:
# 簡單用某個搜尋 API 或直接打特定網站...
...
然後由 Executor 在 sandbox 裡跑簡單測試(例如 basic import,簡單呼叫測試)。
4. Executor(執行器)
職責:有了工具後,照 Planner 所列的步驟跑整個 pipeline
- 用
search_web找到 Adobe 產品頁 URL - 抓取網頁 HTML
- 用內建/現有 parser 清洗出產品清單
產生最終輸出 result。
5. Evaluator(評估器)
職責:拿 result 跟你提供的 gold_output 做比對
- 完全符合 → 任務成功,紀錄「這套工具組合 OK」
- 不符合 → 任務失敗 → 丟給 Diagnoser 分析問題
支援多種評估方法:
exact_match:完全匹配partial_match:部分匹配(計算關鍵字匹配度)semantic_similarity:使用 LLM 評估語義相似度
6. Diagnoser(診斷器)
職責:看 log、錯誤訊息、差異,總結失敗原因並推薦下一步
例如:
- 「search_web 只能抓靜態頁面,但該頁是動態網站 → 需要 render_dynamic_page 能力」
- 「HTML 很亂,裡面有很多無關資訊 → 需要一個更強的 clean_html / extract_products 工具」
然後回到 Tool Builder → 產生新工具 → 再跑一次任務。
這就是構想中的演化循環:
- STEP1:缺搜尋 → 生
search_web - STEP2:缺動態渲染 → 生
render_dynamic_page - STEP3:缺清洗 → 生
clean_product_list
固定不變的基底
這些是「基底」,先建好,以後不動它:
1. LLM API 本身
就是現在在用的 GPT 類,作為「大腦」。
2. Python 執行環境(sandbox)
- 可以動態建立檔案、import 新的工具
- 可以限制權限(避免亂刪檔、亂打 API)
3. 工具註冊中心(Tool Registry)
一個簡單的結構,例如:
{
"search_web": {
"type": "python_function",
"path": "tools/search_web.py",
"signature": "search_web(query: str) -> str",
"description": "用 HTTP 抓靜態網頁"
},
"render_dynamic_page": {
"type": "python_function",
"path": "tools/render_dynamic_page.py",
"signature": "render_dynamic_page(url: str) -> str",
"description": "用 Playwright/Selenium 把動態網站渲染成 HTML"
}
}
由 agent 來「新增」與「修改」這個列表裡的工具。
4. 任務與標準答案 Dataset
你準備的 20 組(或更多):
{
"task_id": "adobe_products",
"instruction": "找出 Adobe 所有的產品,列表輸出",
"gold_output": "...你確認過正確的結果...",
"eval_method": "exact_match / 部分比對策略"
}
訓練方法:從 20 組任務到穩定系統
這裡的「訓練」可以分兩層:
層一:實際工具 / Agent 流程的「搜尋 + 篩選」
這是你一定做得到的:
每個任務:
- 一直跑「嘗試 → 失敗 → 生新工具 → 再試 → 評估」的 loop
- 只保留那些能通過評估的版本(工具代碼 + 使用流程)
久了之後,你會得到:
- 一組 GPT prompt + 一組工具庫 + 一套調用策略,可以穩定解決這 20 組任務
這有點像是:
在搜尋「程式 + 工具組合」,而 Dataset 是你的 20 題考題。
層二:Meta-學習(可選)
如果你有權限做「微調」或「提示工程」,可以進一步做:
把成功的 log 存成「示範資料」
- Prompt:任務描述 + 工具列表 + log
- Output:最終成功的工具調用計畫 / chain-of-thought
拿這些示範:
- 當成「系統 prompt 裡的 few-shot example」
- 或者丟去做微調(如果你能訓練自己的 model)
這樣下次遇到「類似任務」,Planner 一開始就比較有 sense,不用瞎猜那麼多輪。
讓 loop 真的「長出小 agent」
你想要的是:新生出來的不只是 function,而是「小 agent」。實作上可以:
把「能力」抽象為 Agent,而不是一個函式
例如:
SearchAgent- 內部會呼叫
search_web、render_dynamic_page等工具 - 對外只有一個介面:
search_and_extract(query) -> structured_data
- 內部會呼叫
ProductExtractorAgent- 專門負責從 HTML 中抽出產品名稱、分類等。
Loop 的演化方向:
一開始只是「functions」:
search_webrender_dynamic_pageparse_products
當這些 function 穩定後,Planner 可以發現:
- 「每次做『找產品』任務時,都要呼叫這三個工具,順序差不多」
- 然後由 LLM 自己提出:
- 「把它封裝成一個
ProductSearchAgent吧」
- 「把它封裝成一個
Tool Builder 產出一個 class / module:
# agents/product_search_agent.py
from tools.search_web import search_web
from tools.render_dynamic_page import render_dynamic_page
from tools.parse_products import parse_products
class ProductSearchAgent:
def run(self, brand: str) -> list[str]:
# 1. search_web 找到 brand 產品頁
# 2. render_dynamic_page 渲染
# 3. parse_products 萃取
...
- Tool Registry 這時也把
ProductSearchAgent視作一個「能力」,Planner 下次可以直接叫它,不用重新設計 pipeline。
這樣就符合你說的:
手腳甚至包含其他小 agent。
本質上就是:
從「常用工具組合」→ 自動封裝成一個新 agent,並註冊進能力圖譜裡。
現實要注意的三個坑
1. 錯誤的自信 / 幻覺
LLM 很容易「覺得自己做對了」,但實際結果不對。
所以一定要以「可計算的評估」為主(你提供的 gold output),不要相信 LLM 自己說的「我覺得這次結果 OK」。
2. 工具品質很爛歪樓
如果沒測試,它會寫出能跑但邏輯很歪的 code。
至少要有:
- 基本單元測試(型別、簡單案例)
- 效果測試(試跑 2–3 個 sample 任務)
3. 工具爆炸 / 能力重複
時間久了會長出一堆類似功能的工具。
你可以週期性跑一個「Refactor Agent」:
- 看哪些工具功能重疊
- 提議合併 / 清理
- 類似程式碼 refactoring。
實作建議:從最小版本開始
如果你要開始實作這套 loop,我會建議第一步:
準備那 20 個「任務 + 標準答案」(JSON)
建一個最小版的:
- Tool Registry(可以先手動寫幾個工具)
- Executor
- Evaluator(比對 result vs gold)
先讓 LLM 當:
- Planner + Diagnoser,但先不要讓它自改 code
- 先觀察它會怎麼提出「我缺什麼能力」,你再人工寫工具
等這套流程穩定後,再把「人工寫工具」一步換成 Tool Builder + Python 寫檔。
實際應用場景
這個架構特別適合:
- 需要不斷適應新資料來源的任務:例如從不同網站抓取產品資訊
- 任務類型相似但細節不同的場景:例如「找出 X 公司的所有產品」
- 需要組合多種能力的複雜任務:例如「搜尋 → 解析 → 清洗 → 格式化」
總結
自我演化的 Agent 架構提供了一個新的思路:不是預先定義所有能力,而是讓系統在執行任務的過程中自動長出所需的能力。
這種方法的優勢:
- 適應性強:遇到新需求時自動演化
- 可累積:每次解決任務都會留下可重用的工具
- 成本可控:只需要 20 組高品質的訓練資料,不需要大量標註
當然,這也帶來新的挑戰:
- 需要更嚴格的評估機制
- 需要防止工具品質問題
- 需要管理工具庫的複雜度
但整體來說,這是一個值得探索的方向,特別是在需要處理多樣化任務的場景中。